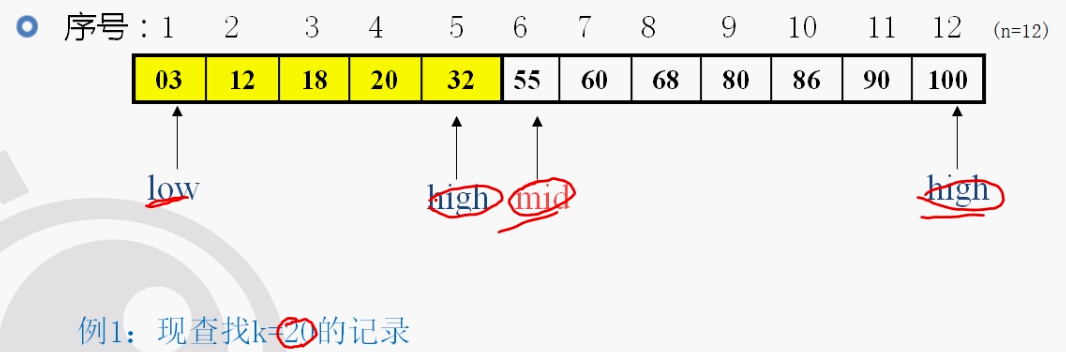
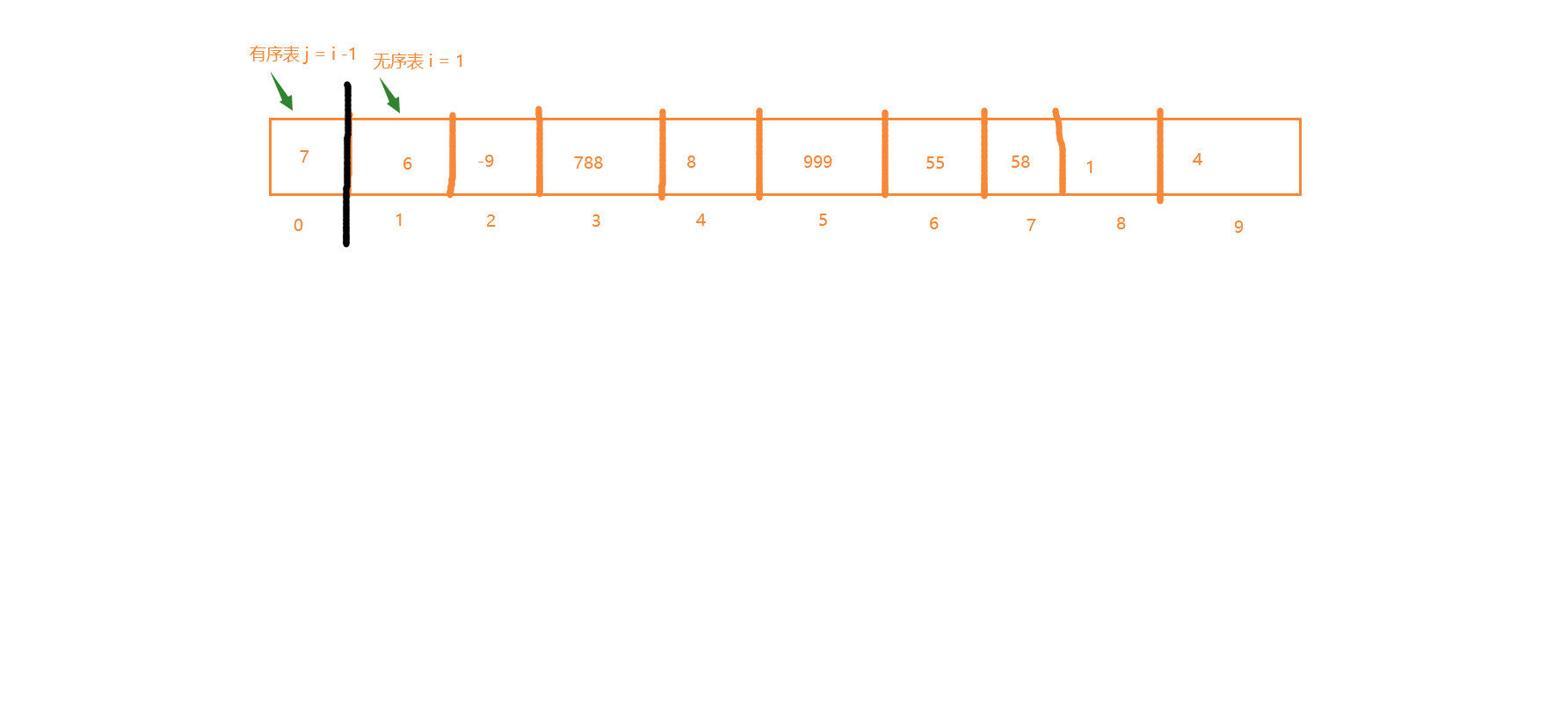
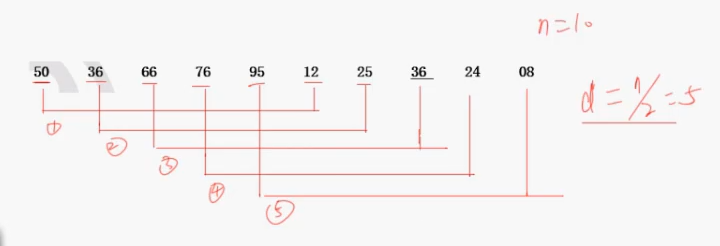
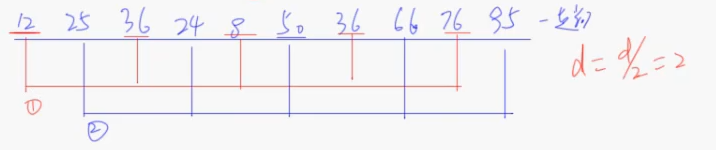
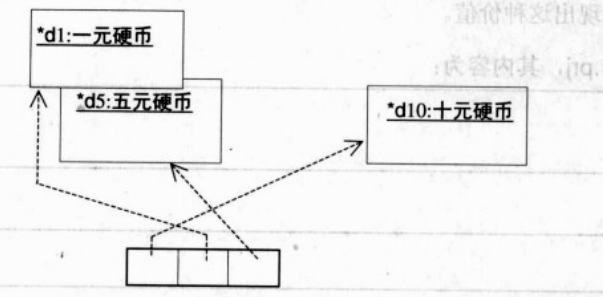
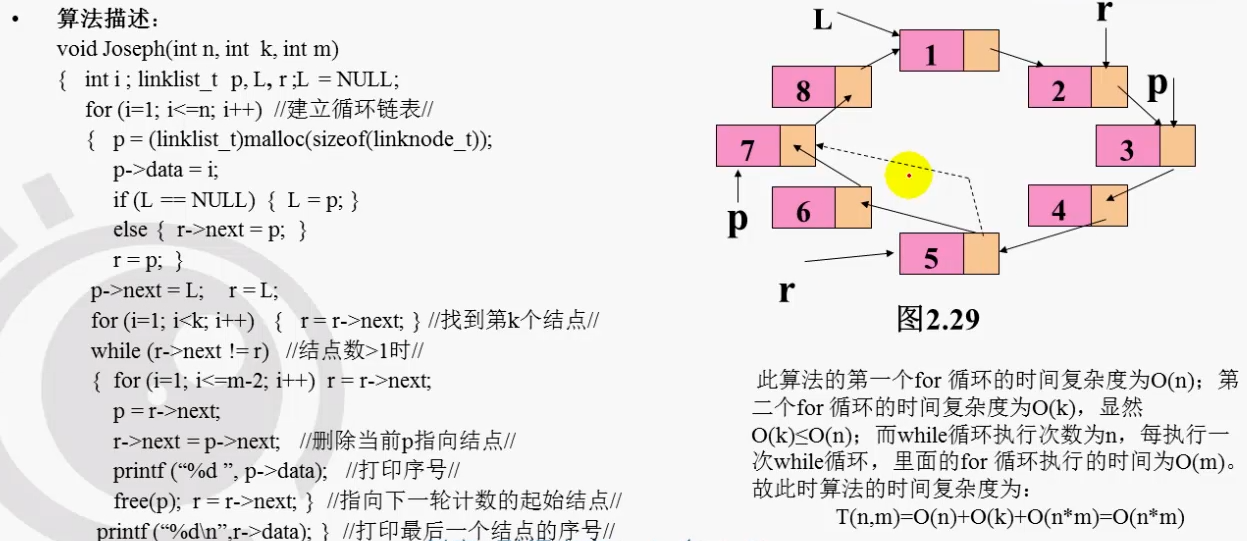
约瑟夫算法:
1 |
|
单项循环链表的删除原则:要想删除一个节点,先找到要删除节点的前一个节点。将前一个节点的next指向,它的next->next。删除之前先保存要删除的节点,后面用来释放空间。
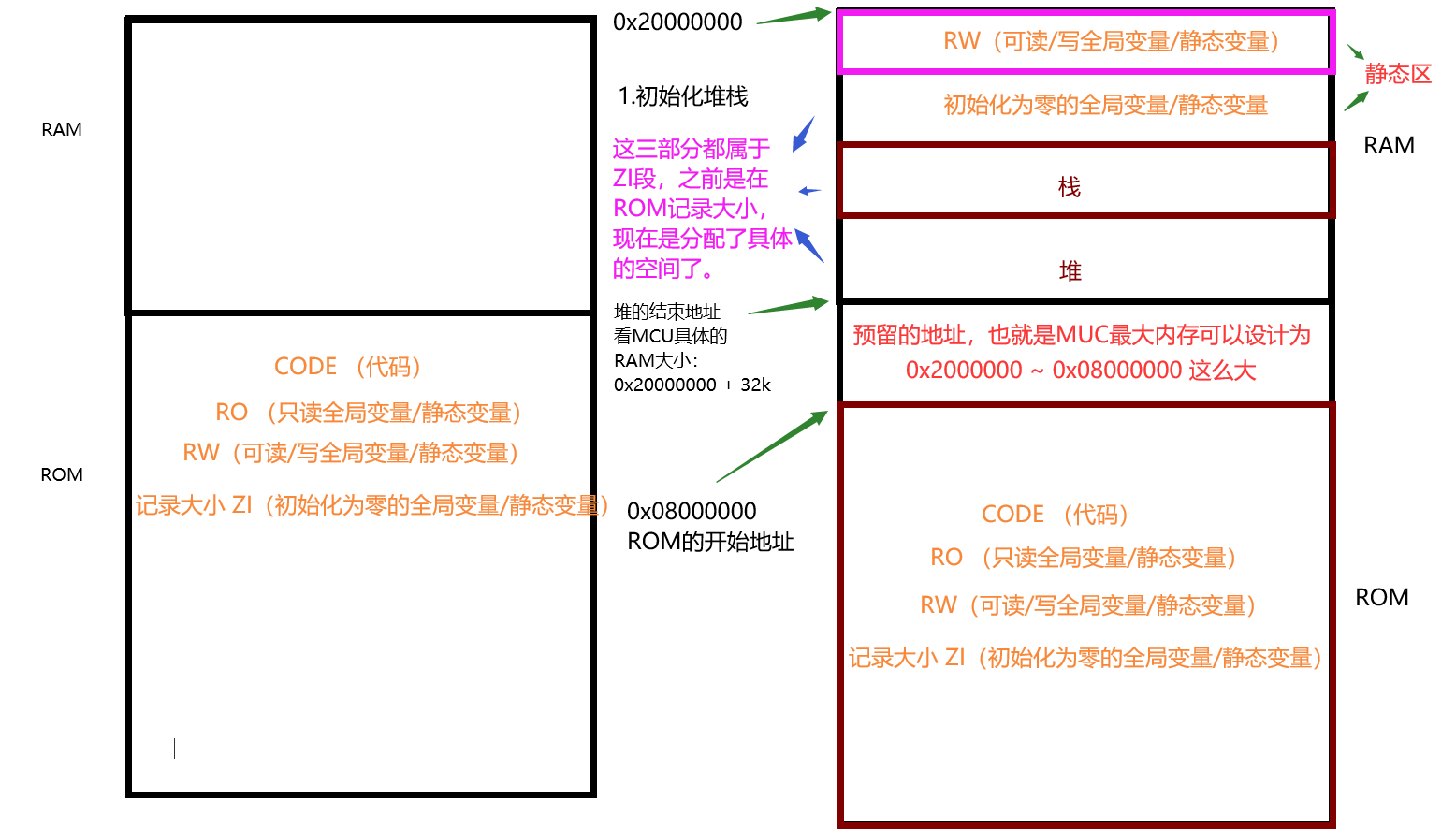
C语言运行的基本环境就是要有堆栈,因为C语言函数调用、函数内变量、参数的传递都是保存到堆栈空间。研究嵌入式启动流程,你会发现,在系统上电后,在跳入第一个C语言函数之前,必须要初始化栈空间的(初始化RAM后,给栈指针寄存器赋初值)。
一般来讲,函数内的局部变量、需要传递的参数,都是保存在栈内的。一个函数可以多层级调用函数,每调用一层函数,都有一个基本的栈帧,保存当前函数的局部变量、参数、临时变量等。每个栈帧都会依次放到栈空间,形成一个回溯链表结构(每个栈帧会有一个成员结构保存上一层caller的栈帧地址),这样函数返回、查看函数调用链都可以通过栈帧链表完成。这些都是通过编译器完成的,编译器通过生成对应的汇编代码,用栈的形式来维护、管理这些函数的变量、参数。
而堆空间这段内存,一般放在BSS段的后面。我们使用C库函数malloc/free申请的内存空间都是放在这段空间内。用户可以通过C标准库函数malloc/free进行内存的动态申请和释放。
1.C语言用户要设置栈的大小,告诉编译器运行时要创建多大的栈,栈底的下一个字节接着就是堆区。
2.有些MCU的堆栈是硬件实现的,用户不能改变栈顶和栈的大小,优点是硬件实现不用执行很多代码消耗时间,只需一条pop或push指令,硬件自动管理堆栈。
Cotex-M3
栈和队列:
- 顺序储存的栈
因为栈的操作都是在栈头(栈顶)进行插入删除的操作,通常叫pop和push。所以使用一段连续的内存存储栈就能满足操作的需要了(不会出现假溢出的情况),可以设计如下栈类型声明:
1 | // 栈类型 |
- 线性储存的栈
线性储存的栈其实就是单链表,只不过单链表的插入删除都在链表头的位置,设计栈类型:
1 | struct stack_frame |
- 顺序储存的队列
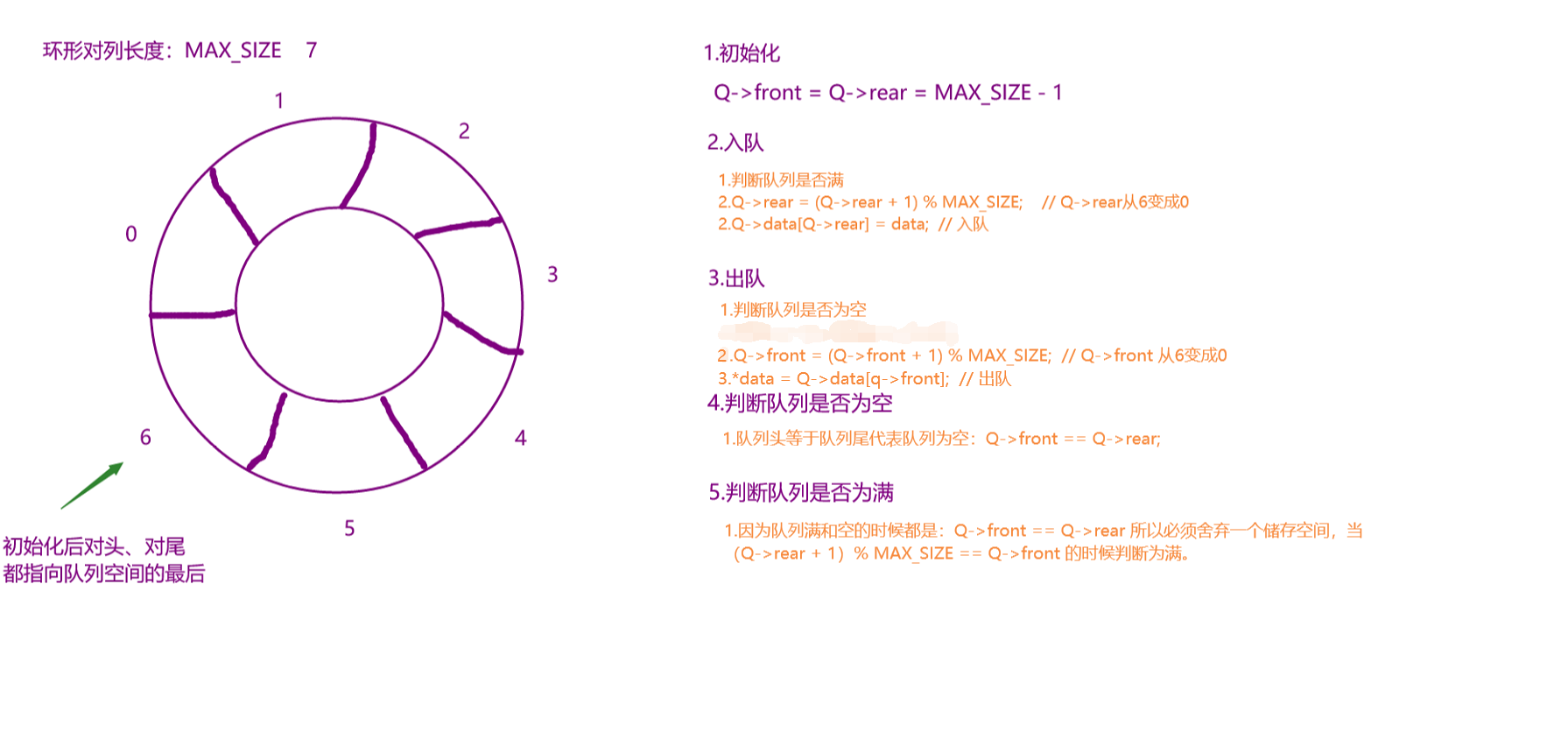
队列使用顺序储存,由于插入是在对尾,删除是在对头,插入和删除在两个不同的位置,因此会出现假溢出的情况,所以需要通过将储存空间的首尾连接起来,使储存空间变成一个环形来解决队列产生假溢出。
假溢出:队列指针达到储存空间的末尾,但储存空间的前部分却没有储存数据,由于rear已经到达数组末尾,但又不可能继续增大数组下标来执行入队操作。这时候需要回到数组开始位置下标为零,才能执行入队操作。
front和rear总是指向要读取或者要写入的前一个节点,开始rear和front都指向6,下一个要读写的就是0。
- 链式储存队列
初始化:
1.链式节点的front和rear都指向链表的头结点,和顺序队列一样,rear和front都指向要读写点的前一个位置。
2.将rear和front指向要读写的前一个位置,是为了链式队列出队时方便从单链表删除要出队的节点。del = q->front->next; q->front->next = del->next;
3.front总是指向head节点, rear总是指向链表的最后一个节点,初始化是front = rear = head;也满足这个结论。
队列类型,消息类型,队列节点类型:
1 | struct message |
队列的创建和判断队列是否为空:
1 | // 创建队列:为队列和队列头申请空间 |
扩展知识:
对于链式队列也可以定义有限储存空间的队列,数据类型如下:
需要维护两条链表:链表1:front到rear已使用节点组成的链表,链表2:free到NULL组成的链表,具体实现方法参考RTOS的消息队列。
初始化:
1.创建空闲链表和非空链表,非空链表front和rear都指向NULL,空闲链表free也指向NULL。
2.把内存空间的所有节点都插入到空闲链表free。
入队:从空闲链表头取一个节点填充用户的数据,在插入到非空闲列表尾。
出队:从非空闲链表头取节点,然后插入到空闲链表尾。
1 | struct message |
队列限制空间大小的利弊:
1.在初始化的时候根据队列能容纳的最大消息数一次性为队列申请总空间,在入队的时候就不需要再申请了。
2.一次性申请内存在嵌入式系统中有个好处:可以减少小块内存的申请和释放, 每次入队申请小块内存、每次出队释放小块内存,会给系统带来内存碎片。
3.坏处:1) 队列只要创建就会占用最大空间,不管队列中有几条消息。2) 队列能储存的消息数在创建时被确定,超过最大消息容量则会放不下。
4.一次性申请可以采用静态定义方式或一次性申请大内存方式,动态实时申请的方式必须要实现动态malloc内存管理。