
查找
查找的方法种类:
顺序查找、折半查找、分块查找、树表查找及Hash表查找等等。查找算法的优劣将影响计算机的使用效率,应根据应用场合选择相应的查找算法。
key:关键字,主key:一定不会有重复的关键字。
记录:一条数据项。
监视哨:顺序表的头节点不用于储存记录,用于在查找时记录要查找key,从顺序表尾网前遍历,如果没有一条记录和key匹配,头节点一定是匹配的(头结点是刚刚写进去的key),查找结构将返回0,代表没有查找到。
不用监视哨查找失败就是返回-1。
- 顺序查找
从尾到头依次比较每条记录和key是否相等
- 折半查找
折半查找的记录必须是有序的记录。
每次取low和high的中间那条记录和key比较,不断缩减查找的范围low~high。直到匹配查找成功,或者查找的范围为的 high < low 代表查找失败。
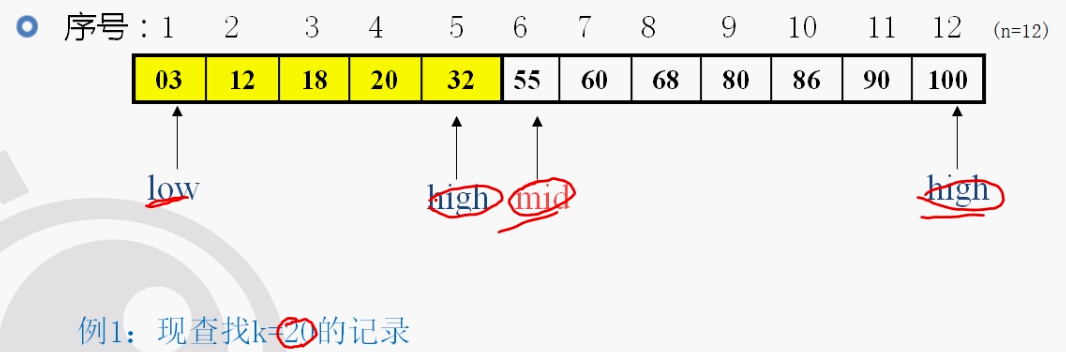

小结:优点:折半查找对存在大量记录时效率高,缺点:记录必须要有序排列。
- Hash表查找
将记录和储存位置建立关系,得到一张表,通过hash表(位置表)就能算出位置里面的值。达到不需要每次查找都要比较很多次的缺点。
映射:字面量到值建立关系。建立关系的:H(key) – f –> key,f 叫做hash函数。实际是个地址映射函数。
冲突:不同的key通过哈希函数可能得到同一个地址。
减少冲突方法:选取hash表时尽量使记录均匀分布在地址范围内。
hash函数
链表地址法:
把有冲突的都串在一个链表里。

排序
基本概念:
稳定排序和非稳定排序:相同记录排序后的顺序。
内排序和外排序:记录储存的位置,RAM或者FLASH。

主要讲的是内排序,记录储存在内存中的排序。
内排序分类:插入排序、交换排序、选择排序、归并排序、基数排序。
- 直接插入排序
1 | /* 直接插入排序算法 */ |
直接插入排序:1.直接:从头到尾每次逐个比较简单粗暴,2.插入:通过比较后找到插入点进行一次插入。
小结:如果待排序的是链表而不是顺序表采用此方法效率更高,因为插入节点后的所有节点不需要一次向后移到,如果记录很多在查找有序表的时候可以再增加采用折半查找法提高查找效率。
- shell排序算法
直接排序算法的改进:将需要排序的记录分组,分成若干个子记录组,首先在若干个子记录组内部直接插入排序。
1.分组:按增量分组,初始增量:d = N / 2
2.对每组交替直接插入排序
3.逐渐减小增量
过程:
1.将10个记录分成5组子记录,增量为 10 /2 = 5
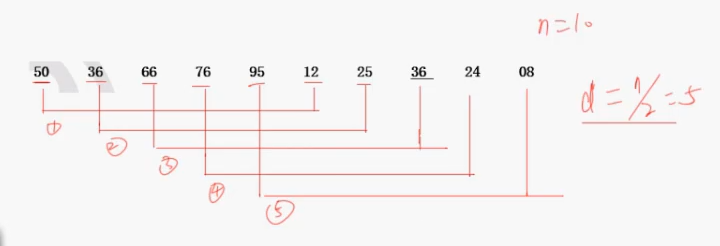
2.对每组进行直接插入排序
排序后结果:12 、25 、 36 、24、8、50、36、66、76、95
3.继续缩小分组的增量得到新的2个记录组,增量等于是那个一次增量 / 2:5 / 2 = 2
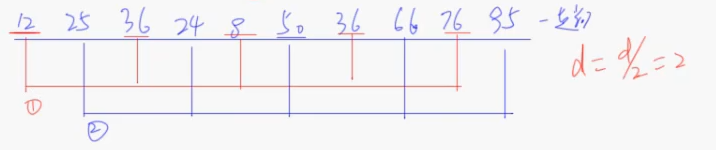
排序后结果:8、24、12、25、36、50、36、66、76、95
4.再继续缩减增量:2 / 2 = 1
排序后结果:8、12、24、25、36、36、50、66、76、95
5.增量:1 / 2 = 0,增量 d < 0 排序结束。
1 | /* shell排序 */ |
小结:shell排序内部采用直接插入排序,将记录分组,对各个记录“跳跃”式的排序,然后调整记录分组的个数,这样总的key的比较次数有所减少,尤其是记录移到的次数大大降低。
- 快速排序
直接插入排序属于插入排序,快速排序属于交换排序。
一般把记录的第一个元素作为基准
通过一趟排序下来,确定基准的位置,基准左边的数都小于基准,基准右边的数都大于基准。
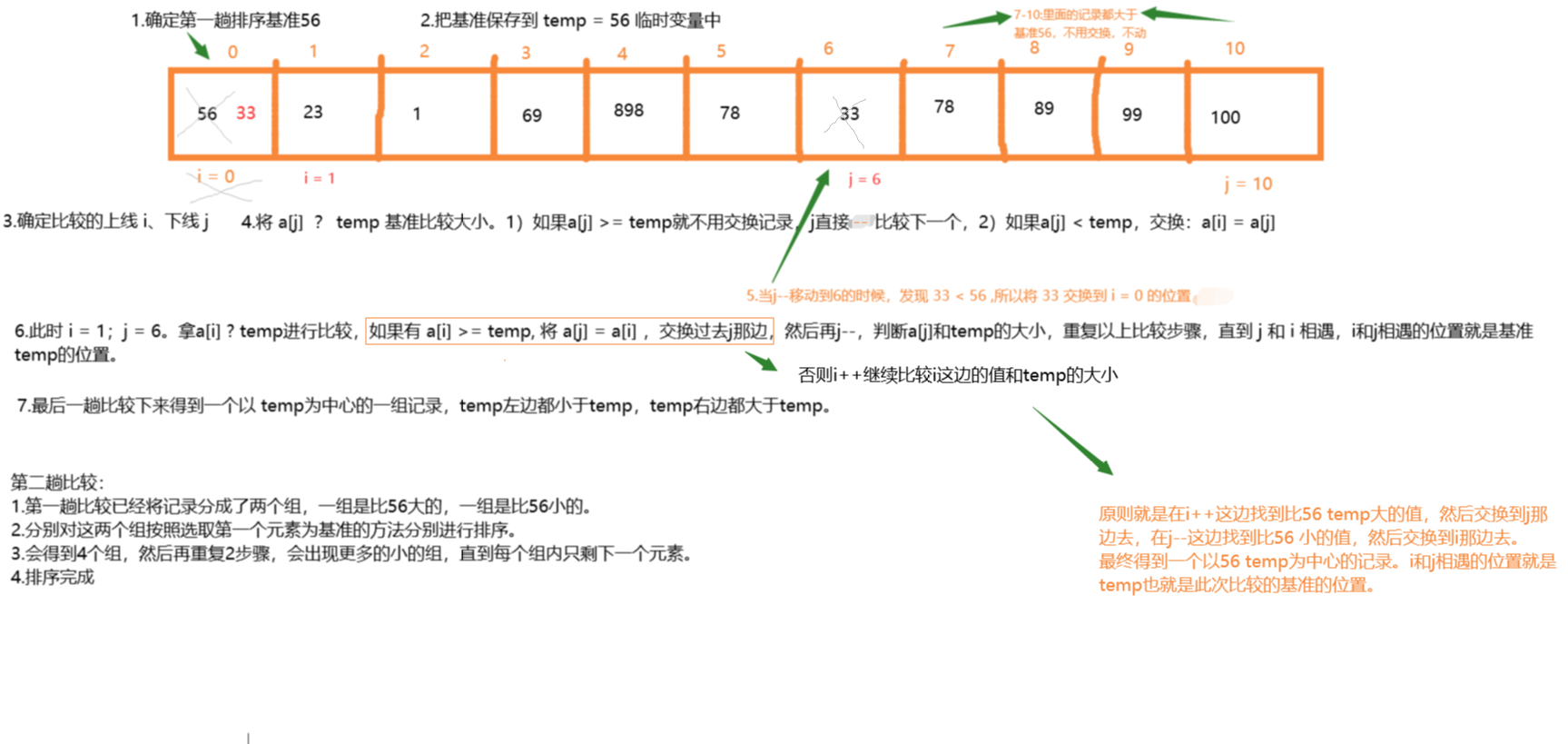
通过一趟排序,确定了基准最终的位置,并得到两组小的记录(基准不在其中),下一趟排序本次的基准就不参与了。之后不断得到更多的记录小组,记录组中的成员不断减小,直到没有组可分,也就是素有的元素都成了某一趟比较的基准。
递归实现快速排序:
因为每趟的排序的操作都是一样的,但前一趟的排序后才能产生新的记录组,才能接着对新的记录组排序,所以可以采用递归函数。
1.确定第一个节点为基准,对需要排序的记录进行快速排序。
2.得到两组新的记录,然后确定两组中的第一个节点为基准,再随这两个组进行快速排序。
3.直到有所记录组基准两边都没有元素:一分配基准后就有 i = j,这就是递归的结束条件。
1 | /* 一趟快速排序 */ |
小结:快速排序的思想就是交换,在low和high区域,在low++边找到大于基准的值就交换给high边,然后再在hight–边找一个小于基准的值交换给low边,直到low和high相遇。
代码仓库:http://gitea.880755.xyz/private/sort.git


- 本文作者: 龙兄嵌入式
- 本文链接: https://hexo.880755.xyz/1970/01/01/zblog/download/86.查找和排序/